Is it possible to assess API health and quality? Can we establish enterprise-scale API governance while holding a single owner responsible for each API? Is it feasible to drive positive change and enhance enterprise API production by prioritizing transparency, actionable feedback, and recovery paths?
This article is presented to you by Swapnil Sapar, Principal Engineer at PayPal. He gave a presentation at the APIDays New York 2023, emphasizing the importance of API quality and accountability. He discussed achieving API governance by embedding automated, actionable feedback throughout the API lifecycle. Swapnil’s insights are enlightening, which is why we invited him to contribute a guest article to the Pronovix blog. Below, he shares his knowledge and guidance .
Ecosystems for API Consumers vs Producers
When it comes to APIs products, users generally fall into two categories: API consumers and API producers.

The API consumer space has evolved much better in the last few years. The overall consumer experience of discovering, evaluating, integrating and observing has improved a lot, thanks to schema standards and toolsets from open-source and vendor offerings.
In contrast, the API producer ecosystem is yet to evolve with such a rich ecosystem of standardized tools and processes. This is even more challenging if you are dealing with a large portfolio of APIs at an enterprise-scale. If you are one of those teams responsible for defining how that API production factory should scale or you are a vendor building API platform tooling, the following approach may help you shape up your offering to your stakeholders.
The API Health Dashboard
What if there is a way to assess and visualize the health of the entire API production factory of an enterprise from the inside? An automated system that is trusted to detect gaps in each of those lifecycle stages, classify those issues into severity, evaluate them with simple grades and then link them to a single accountable party in the organization so that they can take action and improve their health.
For such a system to be successful, we first need to start building trust among the stakeholders that this is the path that would lead us to be successful API producers. In this system, developers are at the center, and they should be able to drill down into those gaps to find enough information and guidance to take action to resolve those issues.
In the API health dashboard, stakeholders are empowered with a fully transparent system that helps them identify issues in their API production and provides hits to take corrective actions. Overall, it elevates the quality of the API, and that leads to
- increased adoption,
- customer satisfaction,
- and greater business success.
API Lifecycle and Signals
As APIs make their way into this production factory, they go through various distinct lifecycle phases: define, design, develop, test, deploy, and operate. Every lifecycle is capable of producing signals about how well it’s working and what issues it’s facing. Let's see those phases and signals.
- Define: An API is proposed and a pipeline is provisioned in this initial phase. Issues in this phase could arise because of situations like: proposed API failed to discover an existing API with similar capability or a proposed API visibility is incorrectly set to public even though its customers are internal. Another one could be a new API pipeline failing to provision its catalog, repo, service or builds.
- Design: This is where actual specifications are drafted using industry standard format e.g. OpenAPI. Issues in this phase could be surfaced are linter (e.g. Spectral) errors and warnings, design violations, scope defined but does not exist in the identity domain, etc.
- Develop: We realize the above API design by implementing it as a service and build actual business logic in this develop phase. Many times it begins with codegen and that may spit errors and warnings or even generate incorrect code. Traditional service software checks apply here code styles, quality, coverage etc. A series of security checks can be performed here in the CI pipeline and report issues like additional operation found in the implementation that is not defined in the openapi.yaml.
- Test: Here we focus on end-to-end testing, contract testing, performance testing, exploratory testing, and even more security scans. Any of those test failures becomes the source of issues for our analysis.
- Deploy: We get ready to productionize our API in this phase. We deploy services, register them on the gateway, and setup API consumer experiences like API Reference Documentation. Example Signals: documentation generation pipeline is reporting failures, Postman collection could not be generated, gateway registration failed, sandbox test failed, etc.
- Operate: Here we monitor and observe engineering and the business KPIs of API that assess the success of the same against the goals with which we thought of creating this API product. API continues to upgrade and evolve in this phase. Issues like breaking change detected, drop in latency, availability, or even CSAT are opportunities for us to tap into those signals that we are interested in for our analysis of API Health.
All of these stages offer different signals that can be tapped through the API lifecycle. With more features, capabilities, and APIs, the lifecycle repeats itself, until some kind of deprecation or a creation of a new style of API comes into play.
During these phases, the product, the market requirements, and the customer journey are changing, and we need to be able to adapt to the new challenges. That is why we need to follow the stages, and be aware of the signals.
Understanding the Signals
How can we read the above-mentioned signals? First, we ingest them into our system using: analyze, visualize and actionize. All this continues while trying to improve the quality of the original signal by removing false negatives and false positives.
An important part is that signal analysis phase is assigning them with appropriate Severity classification such as:

- Blocker,
- Critical,
- Major,
- Minor,
- Info.
We have to ensure that every issue is actionable. We must provide enough context through why, where, how, and use links to the documentation. We also produce actionable feedback with hints to recover in the native environment. This is to ensure that accountable owners and stakeholders are able to take corrective action and continue to close the issues, improve the grades and make the API healthy.
So, who are these stakeholders and how this system needs to create experiences for them to suit their distinct roles?
Broadly, I classify these stakeholders into 3 different roles: developers, leaders and executives.
Each of them has knowledge, responsibilities, decision making powers and controls to ensure API production factory continues to remain healthy. All 3 stakeholders can access the same dashboard, but they get to navigate and view the key signals allowing them to make decisions and take actions quickly.
- Developers: API spec developers, implementation engineers. To realize any change in API behavior, ultimately these developers have to lift a finger to write code, fix the code and ship code. They are foundational stakeholders for API production factory.
- Leaders: API reviewers, architects, product manager, engineering manager, sr manager, directors, and so on. They too have to lift a finger to make higher level decisions around planning, backlog, capacity, strategy, skills, trainings, build-vs-buy, costs, and so on.
- Executives: These are very important stakeholders. It’s crucial to give them an accurate summary view of the API production factory. But they are often forgotten in that context. The question is: Can they make strategic decisions, based on the given information?
We begin with a structure like the following. Here we start by identifying a single owner for each API in the system.This single owner principle is non-negotiable for this system to work effectively. Although, a same owner can own more than multiple APIs but a single API cannot be owned by two people in the organization. Co-ownership is not an option in this case.
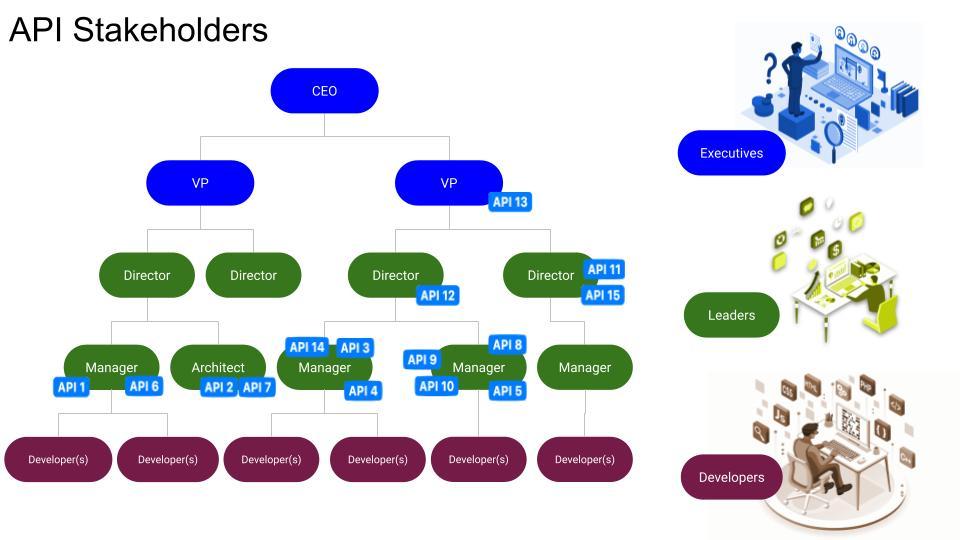
Every API has one owner only, this is a specific leader who could be a engineering manager, product manager, lead architect. Each of those leaders have their own portfolio. A portfolio could contain one or more APIs. A senior leader at the top has an aggregate portfolio of all sub-portfolios plus one or more APIs that they may own directly. This is to ensure that when an owner changes responsibilities or moves out, the system temporarily links them to the leader up the org chart until the replacement owner is identified. We continue to create these portfolios up the organizational chain until executives.
A leader can own multiple APIs, and the leaders and executives have their own set of portfolios.
Portfolio = one or more APIs + one or more sub-portfolios
We roll up all the signals and issues from API lifecycle phases and associate them with the leader’s portfolio.
The Leader’s Portfolio in Practice
Now we can put together everything we have so far. The portfolio relies on a health grade system, where:
- A = Info (API portfolio with no known issues)
- B = Minor (API portfolio with at least 1 minor issue)
- C = Major (API portfolio with at least 1 major issue)
- D = Critical (API portfolio with at least 1 critical issue)
- E = Blocker (API portfolio with at least 1 blocker issue)
If an API has at least one blocker issue, we can mark it with E. The same goes for the other grades. This snapshot view of portfolios and grades is great but time is an important dimension. Knowing how these grades are trending (up or down) over time is critical for stakeholders to assess the result of their past actions and take new actions for the future.
Let’s take a look at a visualized - imaginary - scenario, where a CEO looking at his portfolio of API across different lifecycle phases including historical trends of how the overall health grades are trending):
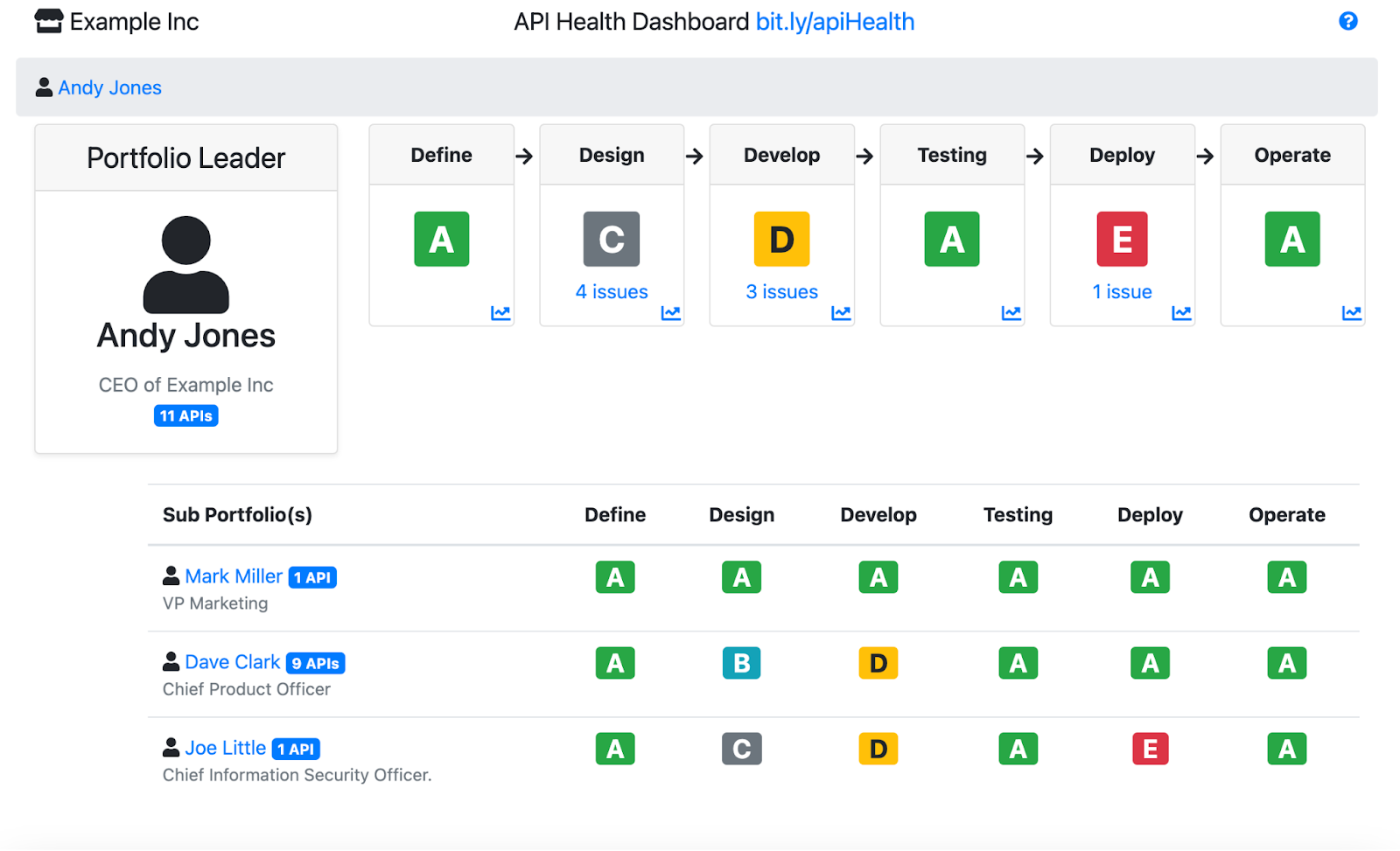
From here, the executives and leaders can quickly learn the overall health of their API portfolio. They can even drill down into any of their sub-portfolios owned by members in their staff until it reaches down to an individual API and its issues thereafter. They can even find how their Portfolio health grades have been trending over time.
Besides giving management a clear idea of how efficient their APIs are, we want to ensure that developers drill down into the API they own, see all the issues associated with it and take actions based on those.
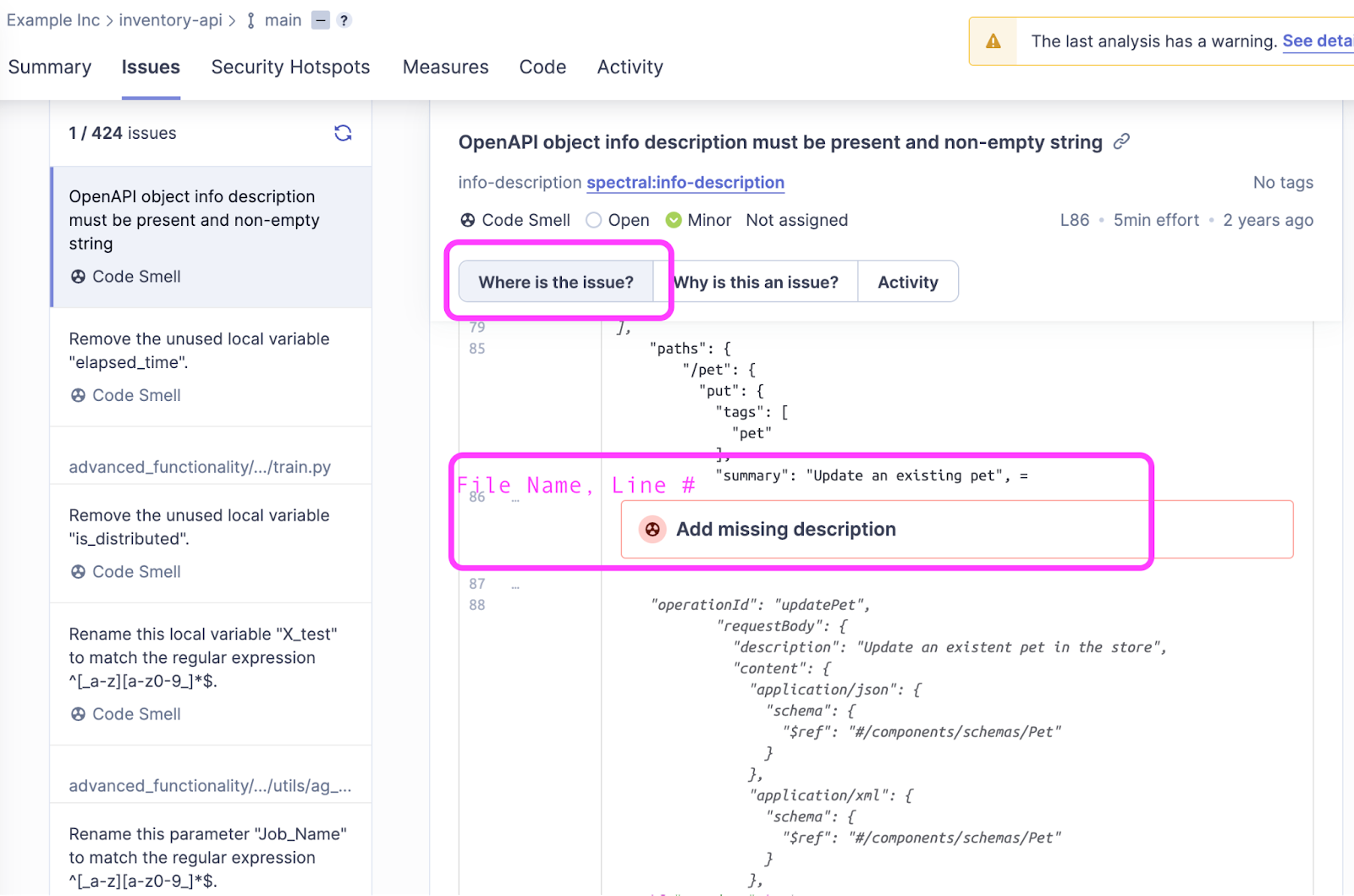
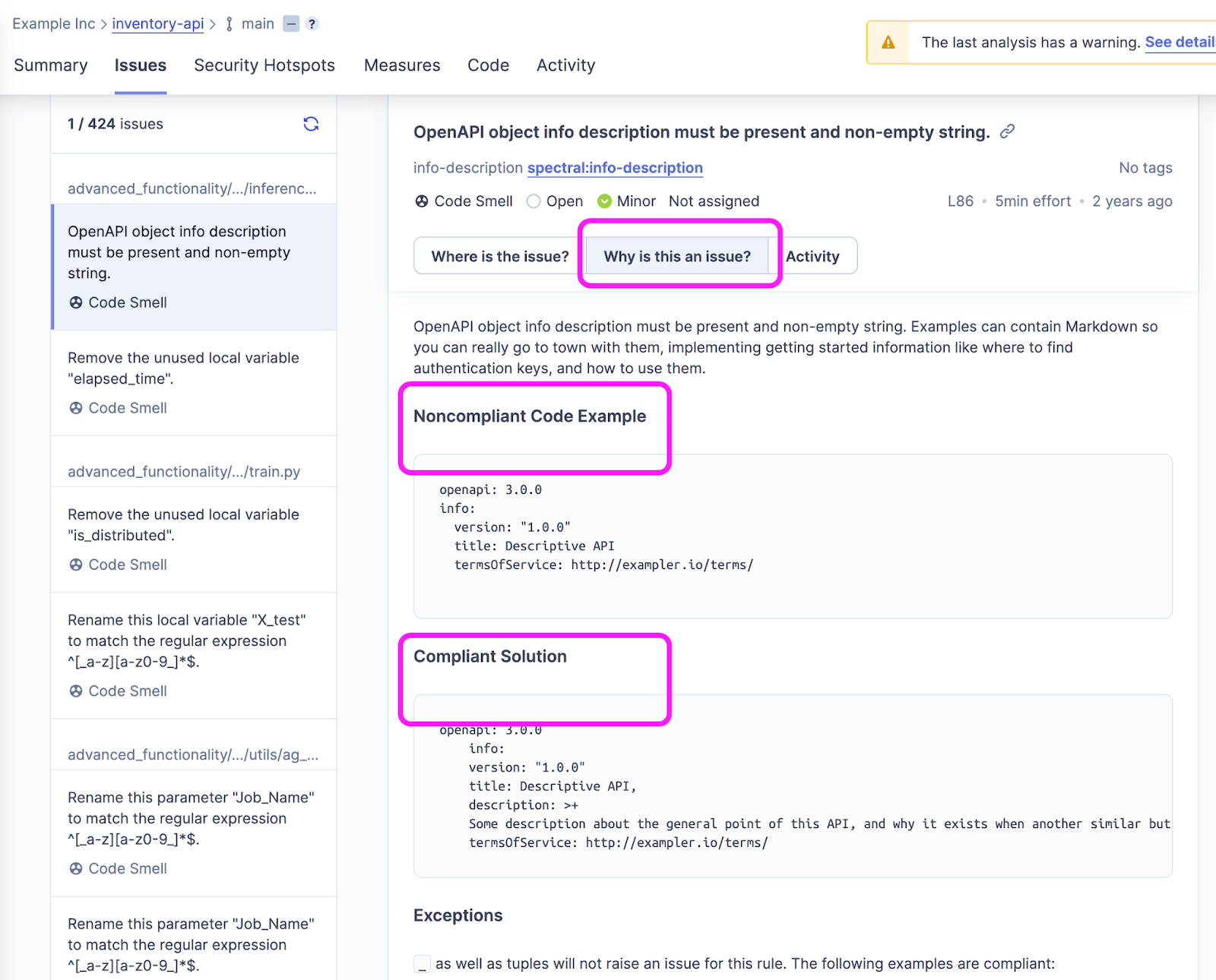
By clicking on the grade, a deep link leads to a list of issues and their severity. Developers can drill down into each of those issues and learn where the issue originated (file name, line number), why that issue is flagged, which policy it’s violating, and finally, most importantly, guidance on how to recover from it in the form of examples of compliant solution.
It is possible to use generative AI in this case. As I see it, we will have two opportunities in the future:
- Producing high quality signals that are not possible using traditional scanning and testing logic like collecting customer (subjective) feedback verbiage, leveraging NL and sentiment analysis, associating that to an API and then creating a new metric: customer satisfaction score.
- Suggesting actions based on a variety of combinations of signals. For example, multiple APIs in a given portfolio consistently reporting design issues, suggesting leader or owner for allocating design training and workshops. Cross referencing portfolio grades' trends with another trending metric like budget, holiday schedule, hiring trends, etc and suggest organizational change to policy, process or people.
Summary
API governance is crucial for enterprise success. By integrating policy guidance as developer signals within their Software Development Life Cycle (SDLC) tools and processes, enterprises achieve higher policy compliance at substantially lower recovery costs. This approach enhances the developer experience and offers management a transparent overview of their API portfolios, facilitating ongoing improvements in API production. The API Health Dashboard, an exemplary governance application for internal portals, provides upper management with a clear perspective on the performance of their APIs.
Related content
- Recording: APIDays New York 2023 - API Quality and Accountability By Swapnil Sapar @paypal
- Mockup of dashboard https://bit.ly/apihealth